
Every business leader exploring AI eventually hits the same wall. The general-purpose AI model you have access to is impressive — but it does not know your products, your policies, your customers, or your industry-specific language. It gives generic answers when you need precise ones.
Two methods have emerged as the most powerful ways to close that gap: Retrieval-Augmented Generation (RAG) and fine-tuning. Both make AI smarter for your specific context. But they work very differently, cost very differently, and suit very different situations.
Here is a plain-English breakdown to help you make the right call.
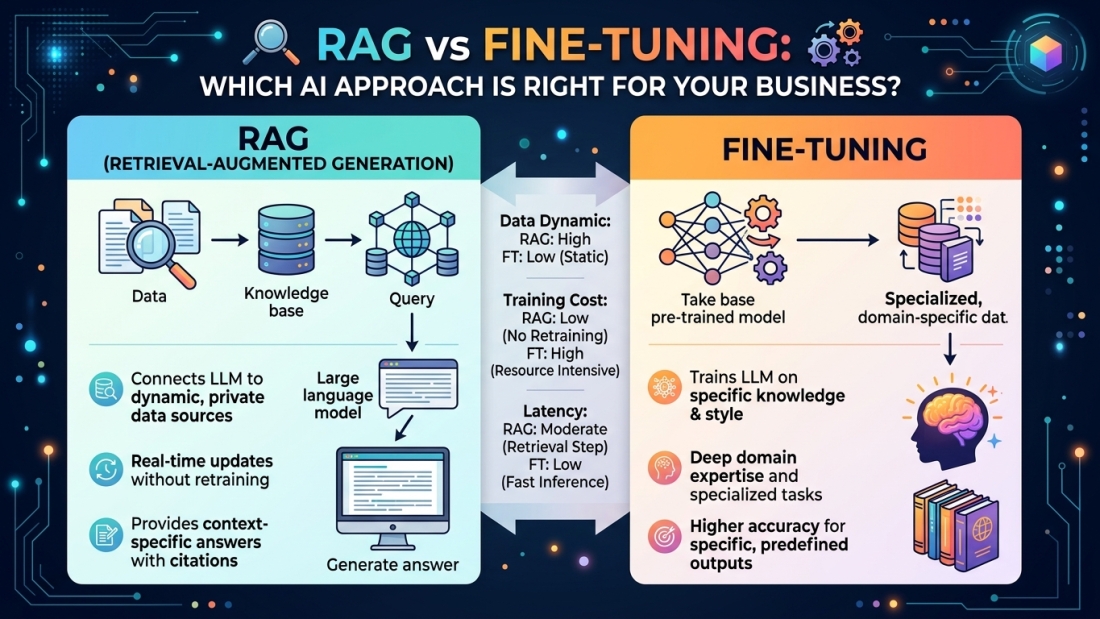
What Is RAG?
Think of a general-purpose AI model as a highly intelligent new hire on their first day. They are sharp, well-read, and quick — but they have never seen your internal documentation, pricing sheets, or customer history.
RAG is the equivalent of handing that employee a live, searchable library of everything your business knows. Instead of relying solely on pre-trained knowledge, a RAG system retrieves relevant content from internal sources — such as documents, databases, or proprietary systems — and uses that context to inform its responses at the moment a question is asked. Glean
The model itself does not change. Its knowledge is extended at runtime through retrieval. This means your data stays current, and the AI’s answers reflect what is actually true today — not what was true when the model was last trained.
RAG works especially well for:
- Customer support bots that pull live product documentation and policies
- Legal and compliance teams that need responses grounded in the latest regulations
- Internal knowledge assistants that search across internal wikis, reports, and HR documents
- Any use case where your data changes frequently
What Is Fine-Tuning?
Fine-tuning takes a different approach entirely. Rather than giving the model external context at query time, fine-tuning involves training a pre-trained LLM on a specific dataset to adapt its behaviour, knowledge, or style — modifying the model’s internal weights through additional training cycles. Is4
The analogy here is less “give the employee a library” and more “put them through a specialist training programme.” After fine-tuning, the model has genuinely internalised your domain — its terminology, its reasoning patterns, its preferred output format.
Fine-tuning works especially well for:
- Consistent brand voice and tone across all AI-generated content
- Specialised tasks with a predictable format — structured reports, code generation, classification
- Medical, legal, or financial use cases where domain jargon and reasoning precision are non-negotiable
- High-volume applications where response latency matters, since no retrieval step is needed
The Real Differences That Drive the Decision
| Factor | RAG | Fine-Tuning |
|---|---|---|
| Data freshness | Always up-to-date | Frozen at training time |
| Cost to implement | Lower upfront | Higher — requires GPU compute and labelled data |
| Technical complexity | Data engineering skills | ML engineering skills |
| Transparency | Can cite sources | Outputs from internal weights — harder to trace |
| Speed | Slight latency from retrieval | Faster at query time |
| Flexibility | Update the knowledge base anytime | Requires retraining to update |
RAG is generally better for most enterprise use cases because it is more secure, scalable, and cost-efficient. It allows for enhanced data privacy, reduces compute resource costs, and provides trustworthy results by pulling from the latest curated datasets. Monte Carlo
That said, fine-tuning has a clear edge when consistent behaviour and deep domain specialisation are the primary requirements — and when your underlying data is stable enough to justify the investment.
The Answer Most Businesses Eventually Reach: Both
The RAG vs fine-tuning debate is often framed as a binary choice. In practice, the most capable enterprise AI systems use both together.
Leading AI practitioners increasingly combine RAG and fine-tuning to leverage their complementary strengths — fine-tuning a model for domain-specific style and terminology, then layering RAG on top for dynamic factual information. This approach delivers consistent, on-brand responses with up-to-date information. Is4
A practical example: fine-tune your model to communicate in your company’s tone and understand your industry’s terminology, then use RAG to pull live product data, customer records, or regulatory updates at the point of need. You get the style consistency of fine-tuning and the factual accuracy of retrieval — without having to choose between them.
So Which One Should You Start With?
For most businesses — particularly those in the GCC, UK, and USA markets that are earlier in their AI journey — RAG is the faster, safer first step. For most organisations starting their AI journey, RAG offers the fastest path to value with lower risk. It is forgiving of mistakes, easy to iterate on, and does not require deep ML expertise. Is4
As your AI use cases mature and your data becomes more structured and stable, you can layer in fine-tuning for the specific applications where it earns its cost.
The wrong move is treating this as a purely technical decision. The right approach depends on your data volatility, your team’s capabilities, your budget, and how frequently your business context changes. Get those factors clear first, and the architecture choice becomes obvious.
At LogIQ Curve, we help businesses across the GCC, USA, and UK design and implement AI systems that are built for real operational needs — not just proof-of-concept demos. Whether you are exploring your first RAG implementation or ready to fine-tune a domain-specific model, our AI and Generative AI team can help you build it right.
Published by LogIQ Curve | AI & Generative AI Services | Serving UAE, Saudi Arabia, Qatar, USA, and UK